I still have to figure out the internals of Informatica BULK target load type. How exactly it works, how it is different from its Normal load, and more importantly how its implementation is different from database to database. Today I have encountered with some issue with bulk load type enabled and ROLLBACKing the transaction (in Informatica) using Transaction Control transformation.
My idea is to issue ROLLBACK after inserting few records into the target. So, I have picked SCOTT.EMP table (in Oracle) as source with ORDER BY EMPNO.
As I wanted to issue ROLLBACK in the half i.e. after loading about 7 records out of 14, I created a Transaction Control Transformation with “IIF(EMPNO = 7782, TC_ROLLBACK_BEFORE)”
This failed with below ORA- error.
Rollback statistics: WRT_8162 =================================================== WRT_8330 Rolled back [6] inserted, [0] deleted, [0] updated rows for the target [EMP] CMN_1022 [ ORA-24795: Illegal ROLLBACK attempt made Database driver error... Function Name : Commit Database driver error... Function Name : Rollback]However, this worked well with Normal target load type. If Informatica’s bulk load type is like Oracle’s INSERT with APPEND hint, direct transaction in Oracle should also fail, but that would not be the case. So, this makes me feel that Informatica has some special handling of BULK load type without completely throwing it to database side.
karteek@orcl10gr2>insert into /*+ APPEND */ emp select * from scott.emp; 14 rows created. karteek@orcl10gr2>rollback; Rollback complete. karteek@orcl10gr2>
- APPEND hint makes the INSERT statement to write the data directly into the data blocks above the high water mark, and more over this supports only INSERT with SELECT clause, but not with VALUES clause where in we pass values for each record.
- Chances are there that Informatica is using an approach similar to BULK COLLECT INTO in Oracle. But, this might not be exactly the same approach, because BULK COLLECT is possible only in PL/SQL.
Update (03/08/2010): (per Srinivas comment below)
I am trying to load the below comma seperated file into a table using direct path enabled in sqlldr.
C:\Users\Karteek\test>type num.dat
1,3
2,4
3,7
SQL>desc tnum; Name Null? Type ----------------------------------------- -------- ---------------------------- A NOT NULL NUMBER B NUMBER SQL> select index_name,status from user_indexes where table_name = 'TNUM'; INDEX_NAME STATUS ------------------------------ -------- TNUM_PK VALID SQL> select * from tnum; no rows selected SQL> $sqlldr karteek control=num.ctl direct=true Password: SQL*Loader: Release 10.2.0.3.0 - Production on Mon Mar 8 11:03:47 2010 Copyright (c) 1982, 2005, Oracle. All rights reserved. Load completed - logical record count 3. SQL> select * from tnum; A B ---------- ---------- 1 3 2 4 3 7 SQL> select index_name,status from user_indexes where table_name = 'TNUM'; INDEX_NAME STATUS ------------------------------ -------- TNUM_PK VALID SQL> exit Disconnected from Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 - Production With the Partitioning, OLAP and Data Mining options C:\Users\Karteek\test>
Happy Holidays!!
Karteek
I just now installed and configured it, and also did a simple "Hello World” kind of test run which went fine.
Quite a simple installtion it was (especially on XP).
There are 2 differences between installation on Windows XP (32bit) and Vista:
- appropriate .Net runtime Vista (it needs 1.1) and
- picking up the right setup files
http://www.mydigitallife.info/2007/12/27/install-microsoft-net-framework-11-on-windows-vista-fix-regsvcsexe-fails-error/
On Windows XP run the batch file “Informatica 8.6\Server\install.bat” for server, and “Informatica 8.6\Client\install.bat” for client (This is a standard approach).
On Vista, this is slightly different. For some reason running the same batch files on Vista in XP compatibility mode is not working (failing while creating Informatica Services, with Error Code – S. Symptoms explained here) – perhaps batch script is not initiating the original installer/.exe files in compatibility mode, may be !
So, as a workaround, run the actual installation files in XP Compatibility Mode as Administrator.
Installation files are as below (in PowerCenter 8.6.0 setup CD):
- Informatica 8.6\Server\Server\Windows\Disk1\InstData\VM\install.exe - for installing server
- Informatica 8.6\Client\Client\Disk1\InstData\VM\install.exe - for installing client
Hope it helps!
Karteek
In the last post I described the approach for installing Informatica Powercenter 7.1 on WIndows Vista . There was something I did on configuring Windows services which I would like to mention here.
When Informtica is installed on Windows with repository on Oracle database, it will show the following services (as display names) in “Services” window.
- OracleServiceORCL10G (there are other Oracle services as well like, but I am not considering them for the current scenario, as this service alone is just enough to describe what I want to say)
- Informatica Repository Server (PmRepServer)
- Informatica (Powermart)
Previously I used to keep Oracle in “Automatic” startup option so that Oracle database is available as my machine boots up (means I do not have to manually bring it up). I had wished the same effect for both Informatica services as well, so that I did not have to start them every time I reboot my machine. Problem was that there is a dependency among these 3 services. Rep service can not start unless Oracle database is available (since Rep service requires rep database), and Informatica service can not start without Rep service in place running. Due to these dependencies among services and I did not set up any dependency rule between them, they all used to start their services at one time (after system reboots), but only Oracle used to succeed as Oracle does not have dependency on others (at least not on other 2 Informatica services).
I always overlooked the “Dependencies” tab that is there when you open properties of a service (Right click on service and choose Properties). But the last time, while I was installing Infa 7.1 on my Vista laptop I gave a close look at, and realized that that was something useful for me. You can very easily define the dependencies between services so that they start or stop in order.
The following steps need to be performed in order to create a dependency (Consider taking backup of current registry settings)
- Run 'regedit' to open your registry.
- Navigate to HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services and locate the service that you need to set a dependency for. (here you need to search for service name, not display name i.e. locate PmRepServer not “Informatica Repository Server”)
- Open the 'DependOnService' key on the right side. If the selected service does not have a 'DependOnService' key, then create one by right-clicking and selecting New > Multi-String Value.
- In the value field, enter the names of all services that the current service will depend on. Each service name must be entered properly (again, it should be service name, not disaplay name) and on a separate line.
- Click OK
Perform the step 2 and 3 for both “Informatica Repository Server” (PmRepServer) with “OracleServiceORCL10G” as DependOnService, and “Informatica” (Powermart) as DependOnService on “Informatica Repository Server”.
This setup makes sure that the service start happens only in “OracleServiceORCL10G > Informatica Repository Server > Informatica” order, and the service stop in reverse order.
There is a new Startup Type option introduced in Windows Vista called “Automatic (Delayed Start)”. I feel this is another good feature. This option delays the Automatic starting up of services for some time (may be few seconds) until the machine boot-up is completely done (you can avoid/reduce the painful slow/no responses on restarts). I enabled this option on “OracleServiceORCL10G” service. Anyway, other 2 services are now dependent on Oracle service, so enabling delayed startup type explicitly would have no additional effect, so they are just “Automatic” startup type.
Hope it helps!
Karteek
However the major drawback I personally felt with Vista is its compatibility with many software especially in the midst of its reviews there is even no hope that software vendors put any efforts to release Vista compatible packages. Most of the software in BI space are not compatible on Vista. So, I dared to use virtual machine with XP on it so that I can do my works. But the performance of VM was really bad, and I could not do any work on it - it spoiled both host and guests. It has been more than 1 month that I did not run VM at least once :(.
Yesterday, I was browsing Oracle.com and noticed Oracle 10g for Vista is available for download - don't know since when it was there, but my bad I did not notice it until yesterday. I downloaded and installed it - cool, it's working. And then I started trying with Informatica 7.1. I know it is not compatible on Vista, but kept trying resolving entire issues one after other, and finally Informatica 7.1 on Vista - it worked!
I got some strange errors like a few below while I was trying installation. Most of the part is just same as it was on XP when I did last time. Entire credit should go to Vista! Yes, truly. Though Informatica 7.1 does not have any compatibility, Vista has opened its windows to host this software with its amazing "Compatibility" feature.
Here are the steps...
Create a database user (repo/repo@orcl) with necessary privileges like Create Session, Create table etc... – This user is required for holding the Informatica repository objects (will be used in the steps explained below).
Steps below are for configuring Informatica 7.1 on Windows Vista:
1. Run Launch.exe in compatibility mode (Windows XP)
2. After installation (Product License Key is required)
3. Setup Repository and Informatica servers (steps below)
a. Informatica Repository Server Setup - with defaults unchanged, give password for Administrator
b. Informatica Server Setup –
i. Give Informatica server name (INFA_SERVER) and hostname (localhost) in Server tab
ii. Give Repository name (REP_SERVER), repository user (Administrator - pwd for this user comes from step 3a), repository hostname (localhost) in Repository tab
iii. Add licences in Licenses tab (not required to add Product License, but others like Connectiviy, Partitioning etc).
4. Go to Windows Services and start "Informatica Repository Server" service (PmRepServer) – this uses details entered in 3a.
5. Open “Repository Server Administrator Console”
a. Right click on "Informatica Repository Servers" and click "New Server Registration"
b. Enter the hostname given in step 3b in Repository tab (localhost).
c. Above entered hostname will appear in the server list. Right click on the entered hostname and click "Connect"
d. Enter the administrator password given in step 3a
e. Right click on the folder called "Repositories" and click "New Repository"
i. Enter the repository server name that is entered in step 3b in General tab (not required to choose Global Repository check box)
ii. Enter database details (DBUser, DBPassword, ConnetString) in Database Connection tab.
iii. Add the licences, including product license in Licenses tab
iv. Click Ok - this will start creating the repository tables in the database location specified above.
6. Go to Windows Services and start “Informatica” service (Powermart) – this uses details entered in 3b.
7. Open "Repository Manager" and connect to repository (REP_SERVER) using Administrator and its password
8. To create additional user (recommended), go to "Security" menu and click "Manage Users and Privileges" and add a user.
9. Create a folder - go to "Folder" menu item and create. Change owner of folder to the user created in above step
10. Go to Workflow Manager (Run as Administrator) and login with Administrator and click "Server Configuration" under "Server" menu
a. Add New server - give server name and hostname as given in step 3b (INFA_SERVER, hostname), and set "$PMRootDir" in server variables list (C:\Program Files\Informatica PowerCenter 7.1.1\Server). This server will be assigned to a workflow or session when before it has to run.
As I said, very few steps are different in installation on Vista compared to XP.
• For Vista, it's required to install Informatica (Launch.exe) in XP compatibility mode (as Informatica and Vista are not compatible) and
• Run the client applications (Designer, Workflow Manager, probably Monitor as well) as "Run as Administrator".
Below picture lists the files that will be created under "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Informatica PowerCenter 7.1.1" post installation of Informatica 7.1 (after Step 2)

Hope it helps!
I have been working on 8.6 for quite a long time, but never tried setting it up. I am planning that soon, if possible in the next week, with a post collecting my experiences.
Karteek
I was just going through Powercenter Monitor's help guide and noticed a page describing about the different possible statuses that a workflow or a task can be in at a given point in time. I found a status called "Unknown Status" as one possbile status, and per guide here is when it can happen.
Unknown Status
ERROR Wed Oct 7 00:55:09 2009 1409415520 LM_36317 Error in starting execution of workflow [id = 2651] [w_sales_fact]. ERROR Wed Oct 7 00:55:09 2009 1409415520 LM_36363 Workflow [w_sales_fact]: Cannot rename workflow log file [/opt/app/Informatica/pc/server/infa_shared/WorkflowLogs/w_orders_LOAD.log.bin] to [/opt/app/Informatica/pc/server/infa_shared/WorkflowLogs/w_orders_LOAD.log.1.bin]. INFO Wed Oct 7 00:55:01 2009 1409415520 LM_36814 Workflow [w_sales_fact]: Got scheduled request to start workflow. INFO Wed Oct 7 00:55:01 2009 1398925664 LM_36814 Workflow [w_orders]: Got scheduled request to start workflow. INFO Wed Oct 7 00:55:00 2009 183009705024 LM_36813 Workflow [w_sales_fact], run instance name [] is scheduled to run now, schedule last saved by user [karteek]. INFO Wed Oct 7 00:55:00 2009 1388435808 VAR_27029 Use persisted repository value [0] for user-defined workflow/worklet variable:[$$Load_Failed_ctr]. INFO Wed Oct 7 00:55:00 2009 1388435808 VAR_27029 Use persisted repository value [0] for user-defined workflow/worklet variable:[$$Is_LoadFailed]. INFO Wed Oct 7 00:55:00 2009 1388435808 VAR_27027 Use default value [] for user-defined workflow/worklet variable:[$$Delay]. INFO Wed Oct 7 00:55:00 2009 183009705024 LM_36813 Workflow [w_orders], run instance name [] is scheduled to run now, schedule last saved by user [karteek].
select subject_area, task_name workflow_name, attr_value cur_log_name, task_name || '.log' new_log_name from infav8.rep_task_attr a, infav8.rep_all_tasks b where attr_name = 'Workflow Log File Name' and a.task_id = b.task_id and a.version_number = b.version_number and task_name || '.log' <> attr_value -- change pattern in this line order by 1, 2
Hope it helps!
Update 11/28/2009:
I have collected few more situations that can possibly turn a workflow's status into "Unknown Status".
- When a PowerCenter repository have versioning enabled and a dependent activity is still checked out when scheduling the workflow - solve this by checking in all the dependent objects (from Informatica KB - ID: 100943)
- There is a known issue (CR 182478) that has been fixed in PowerCenter 8.6, causing workflow to be in "Unknown Status". To resolve the issue, upgrade to PowerCenter 8.6. However, as a workaround in versions earlier than PowerCenter 8.6, set Save workflow log for these runs to zero (0) in workflow properties (ID: 106278).
When workflow parameter files is defined (in workflow properties), but if either parameter file is not present or no permissions to read it, then also workflow goes into Unknown status (verified in 8.6). Error message would be like one below.
(my_is) Start task: ERROR: Workflow [wf_test]: Parameter file [/opt/app/Informatica/pc/server/infa_shared/SrcFiles/test.prm] not found. Please check the Integration Service log for more information.
Karteek
This is little off from my usual topics. Paul Krugman, an Op-Ed columnist in NYTimes, recently expressed his opinions on mischievous Chinese currency in the world market, and about its implications on the current economy in rest of the world. A nice post to read…(the same post is published in today’s The Hindu daily, in case if you prefer hard copy :) ).
http://www.nytimes.com/2009/10/23/opinion/23krugman.html?_r=1
- Karteek
I am trying something on SAS. It was an alien thing until recently, but should look forward to see how it turns out to be soon. My very intial impression on the software was not so good - didn't really captivate me. However I still have to go a lot deep into it to scratch its surface. Perhaps I will soon have a post on my experiences with it.
So far the best thing I noticed in SAS is its Help - perhaps one of the best manuals I happened to surf through.
Catch you again...
Karteek
Balance between Oracle and Linux - A Troubleshooting Story
0 comments Posted by Karteek at 9/22/2009It's known thing that Oracle and Linux are nicely coupled that the scope of performance issues in Oracle is not just limited to Oracle sometimes... I stumbledupon one cool post by Riyaj (http://orainternals.wordpress.com/) in which he had explained how he troubleshooted the CPU usage issue with an optimal memory configuration.
Recent OS architectures are designed to use all available memory. Therefore, paging daemons doesn’t wake up until free memory falls below a certain threshold. It’s possible for the free memory to drop near zero and then climb up quickly as the paging/swapping daemon starts to work harder and harder. This explains why free memory went down to 78MB and rose to 4.7GB 10 minutes later.
What is using my memory though? /proc/meminfo is useful in understanding that, and it shows that the pagetable size is 5GB. How interesting!
Original post can be found here.
Problem was identified with paging which used BIG pagetable(due to smaller unit page file size, 4KB, and larger memory ~10GB) meaning so many pages (millions - ~ 2.6m) that machine most of the resources in managing the pages itself so nothing left for other any critical processes. He increased the page file size to 2MB and thereby decreasing the pagetable size and main bottleneck was resolved. It's a good read.
- Karteek
In the recent past I have been noticing an SMTP ORA- error while a stored procedure tries to send out an email. Error is below.
PRE-SESS> TM_6159 Error executing stored procedure... TM_6159 [4294965496] [ ORA-29278: SMTP transient error: 421 Service not available ORA-06512: at "SYS.UTL_SMTP", line 20 ORA-06512: at "SYS.UTL_SMTP", line 96 ORA-06512: at "SYS.UTL_SMTP", line 272 ORA-06512: at "SYS.UTL_SMTP", line 248 ORA-06512: at "SYS.UTL_SMTP", line 259 ORA-06512: at "YK.EMAIL_TEST", line 39
I have ignored this error 3 to 4 times as this error was not so frequent, and neither job was so critical. We were hit with error again yesterday, and thought I should give some attention to it. Error says that "SMTP Service no available". It obviously means either SMTP service is not running, or service is unreachable. Point to note is that the failing stored procedure is not using the SMTP service of the host where its database itself residing on - SMTP server is available on a remote machine.
I could sense that SMTP service availability is not the reason for this problem (because other procedures on other databases from different hosts have never faced this error). So, my next suspect is network availability between the database hosting machine (where stored procedure runs) and the SMTP host machine. I had a request to DB team and SYS team to checkthe n/w issues between the two. Let me see how it turns out eventually.
While I was trying to collect some related information on this issue, I could able to find a metalink doc (604763.1) - though it is not addressing my actual problem, but it explained how one can check SMTP service from command line. This is a good learn for me today. A sample mail test from my machine (hydaap01) with SMTP server (hydaap02)
$ telnet hydapp01 25 Trying 124.2.78.2... Connected to hydapp01 (124.2.78.2). Escape character is '^]'. 220 hydapp01 ESMTP Sendmail 8.13.7+Sun/8.13.7; Thu, 17 Sep 2009 06:48:13 -0400 (EDT) helo domain 250 hydapp01 Hello hydapp02 [124.2.78.3], pleased to meet you mail from:yk@hyd.com 250 2.1.0 yk@hyd.com... Sender ok rcpt to:karteek.yelampally1@hyd.com 250 2.1.5 karteek.yelampally1@hyd.com... Recipient ok data 354 Enter mail, end with "." on a line by itself Subject: This is SMPT test using telnet This should be rock successful. . 250 2.0.0 n8HAmDQu006085 Message accepted for delivery quit 221 2.0.0 hydapp01 closing connection Connection closed by foreign host. $
And so I have email in my mail box.
- Karteek
NULL is perhaps one of the most dangerous concept but easily ignored by many. Because its definition it self is not clear or rather not a standard one. Different softwares and applications define NULL differently and so their functionality. I have not got much exposure to numeruos technologies, but so far with my experience Oracle handles NULL very eligantly. Oracle defines NULL as something not defined, so you don't know its value. And more interestingly, both 'NULL = NULL' and 'NULL != NULL' are not true, because when you don't know the value of NULL it can not be compared. By now one more point is clear that NULL and '' (a zero length string) are not same in Oracle - since '' is a knwon value.
Handling NULL is not at all difficult, at least from my experience. All that we need to know is how your environment handles NULL - understanding its definition and little bit testing. Common mistake is many people ignore the very basic truth that NULL in their environment could work differently from thier past experiences with NULL, and face surprises that are usually difficult to debug. It may work differently not just from application to application but even from version to version.
Today, I was caught in surprise when NULL behaved differently from Informatica 7.1 to 8.6. See the below image.

There are many session instances that run cocurrently. All of them are same but they just run for different connections (1 session = 1 source = 1 connection) for which connection names are parameterized. Since number of sources is not static, I have to run this workflow until I finish running a session for every source. If I have 10 concurrent sessions and 47 sources then it would require 5 workflow runs ( 10 + 10 + 10 + 10 + 7). So in that last run I need to run only 7 sessions but not 10, and this is taken care by the link condictions I've specified in between "Start" task and Session instances. In Informatica 8.6 I defined a link as one below...
IS NOTNULL($$DBConnectionSource1)
$$DBConnectionSource1 is a workflow variables that comes from parameter file. Below is the parameter file used for last run (that runs only 7 sessions)
$cat w_source_test.prm [Test_Folder.WF:w_source_test] $$DBConnection1=IDPV1 $$DBConnection2=IDPV2 $$DBConnection3=IDPV3 $$DBConnection4=IDSV1 $$DBConnection5=IDTV1 $$DBConnection6=IMPV1 $$DBConnection7=IMPV2 $
If you notice only 1 through 7 variables are defined. My intention is to keep only the variables in parameter file so that only thier correspnding sessions (based on the link condition) would run.
In 8.6 Informatica it runs as expected (I expected if variable is not defined then it is treated as NULL).
Link [Start --> s_m_source_test_7]: condition is TRUE for the expression [NOT ISNULL($$DBConnection7)] Link [Start --> s_m_source_test_8]: condition is FALSE for the expression [NOT ISNULL($$DBConnection8)]
But in Informatica 7.1 it worked differently. With same parameter file both the links (for sessions 7 and 8) are evaluated false - means not defining the variable was not treated as NULL.
I had to change the link condition like below to make work...
$$DBConnectionSource1 != ''
It worked - 7.1 considered undefined variable value as zero length string (but not as NULL).
Link [Start --> s_m_infa_connection_test_8]: condition is TRUE for the expression [NOT ISNULL($$DBConnection8)]. Link [Start --> s_m_infa_connection_test_9]: condition is FALSE for the expression [$$DBConnection9 != ''].
DBConnection8 was not defined in parameterfile but that was still evaluated to true treating its value as not a NULL, but DBConnection9 link evaluated correctly (to FALSE since value is not set) against zero length string.
So, it's just a point of note, but the bottomline is that we simply just can not ignore NULL as it is nothing set with or undefined, because you never know how that unknown thing is handled by your app.
Update:
Although this post has much talked about Informatica handling NULL, there are some interesting posts of Tom Kyte (of asktom.oracle.com) on handling of NULL in Oracle.
http://tkyte.blogspot.com/2006/01/something-about-nothing.html
http://tkyte.blogspot.com/2006/01/mull-about-null.html
- Karteek
Last week, we were trying to bring an improvement in one of our ETL processes. Process is such that Hyperion cube’s load needs to started just after some ETL loads’ completion. Both Informatica and Hyperion are hosted on different servers, and both are Linux. So, there has to be some dependency established between ETL process on Informatica server and Cube load process so that Cube load gets kicked-off immediately after ETL finishes.
If you feel you do not have much time to conver the full details below, you directly skip to here as main purpose of this post is explain the difficultly I faced in using ssh from Informatica.
We could think of an approach where in trigger file (zero byte file) from ETL to notify Cubes’ load job. But this is very loosely coupled – ETL should either send the trigger on to Hyperion server and Cube load process that already started on Hyperion server should be waiting for the trigger to kick-off cubes load. There are some serious drawbacks in this approach -
Both ETL and Cubes’ load jobs should be scheduled on their servers – how does already started Cube load process know about ETL job failed and that current is ignored – fairly acceptable scenario, I believe. As a work around, Cube load job on Hyperion server can for defined time period, and it still doesn’t find trigger file then stop cubes load – some sort of workable, but still not good when schedule of ETL changed or ETL took longer period. (Trigger file released on to a shared file system instead of sftping is just nothing but a trigger file dependent)
A good possible workaround I could think of is an Enterprise Job Scheduler that reduces if not fully eliminates the process dependency barriers among the different servers. In addition to Informatica and Hyperion servers if there is another third server that controls Jobs on rest of the servers this issue is solved – Job scheduler to start the Cube load process only after ETL finishes.
But not every company uses a Job Server/Scheduler, unless the IT is relatively complex and value for money is not identified. My client is not using the Job scheduler, at least that I know of in their well matured BI department. Just because of some rare (at for them) benefits that Job Scheduler can bring, simply ignoring the classic scheduler that Informatica gives is also not good idea. So be with it.
At this point of time, only option I can think of is remote invocation of Cube load process on Hyperion server from Informatica server as part of its ETL itself – no it’s tightly coupled – process of Hyperion server doesn’t even start unless ETL finishes.
So, point is clear by now – I need to start the Cubes’ load process from Informatica, precisely through a command task calling a remote shell script. A code snippet is something like this…
ssh –q –l hyp01 hypsrvr ‘/opt/app/Hyperion/cube_load.ksh’
I noticed a weird behaviour of this process when it was invoked from Informatica 7.1. Even though cube_load.ksh process on Hyperion server is finished, process on Informatica 7.1 server still shows up in the process list (ps -f) forever, and so does in Informatica monitor. The very same command when executed directly on the server (from putty) worked fine. Even a simple ssh command for “date” gave the same result when ran from Informatica. For the first time I tried to use strace on the PID of ssh process, though not successfully – but that was showing only “select(16, [0 13], [], NULL, NULL” – still not helpful.
ssh –q –l hyp01 hypsrvr ‘date’After breaking my head for couple of hours, I partially suspected pmserver process of Informatica 7.1 (which means Informatica 7.1 it self) which becomes parent process of every process (session, shell command, sql client or anything invoked by Informatica).
I then tried in our other upgraded environment Informatica 8.6 and that worked. I’m suspecting 7.1 has this bug fixed in later releases. I’m not confident enough to say that Informatica 7.1 has this bug, as Linux machine environment settings also a possible reason. So, I deeply appreciate sharing your similar experiences. This is our Informatica Linux server version.
With my boss help I tested rsh too instead ssh – we knew rsh was not the way to go due to the risks involved, we just gave a try and that worked in both 7.1 and 8.6 – only ssh had the problem.
$ uname -svm Linux #1 SMP Wed Jul 12 23:36:53 EDT 2006 i686
Something off the topic I learned from him was how to setup .rhosts for rsh. I knew already how to setup the similar for ssh (generating the public keys on client machine and them to host machine’s authorization keys file), but rsh too has some similarity in the setup. There are no encrypted keys generation required, but just adding the client user name in the remote machine’s HOME/.rhosts file and that works.
As I requested, please do share your experiences with Informatica and ssh together.
Karteek
There is some interesting behaviour that I noticed recently in Informatica's repository with respect to session's run time information. If you are not much comfortable with Informatica repository that I now I am going to explain about, here is some quick notes.
Informatica entire application lies on a data repository that consists of several tables (mostly start with OPB*). Perhaps in order to make an ease access to repository information, Informatica also provided several views based on the OPB tables. For many of the common questions you may want the answer REP views should help, bu there is always an exception and OPB tables are there. When you write queries on OPB tables take due care that you do not ruin database with bad joins - for this Informatica manual gives the columns that generally good candidates for joins when using REP views, but generally the same information applies to joining tables as well since a view is just a named query. Some useful views are... REP_WORKFLOWS - Workflow master list REP_WFLOW_RUN - Worklow run time details REP_ALL_TASKS - Master task list REP_TASK_INST_RUN - Task level run time details REP_SESS_LOG - Session's Success/Failed records etc...
With those details, let me explain the what the prob
em is in 7.1. Workflow_Run_ID uniquely identifies each run of a workflow - means when a workflows starts (starting part of the workflow or full workflow or a schedule run) it would have a new workflow_run_id.
For suspended workflow (enabled "Suspend on Failure"), common way we recover it is by resuming it after the fix is provided (in 8.6 option name is "Recover"), and resuming it obviously not a new run so doesn't carry a new worklflow_run_id after resumed. It also means that there would not be a new entry into REP_WFLOW_RUN (or OPB_WFLOW_RUN table) when a workflow is resumed.
Moving a little back, a workflow goes to suspended state when it's meant to fail by the configuration of underlying tasks - means when underlying task fails that makes it's parent (or workflow in a simple setup) to fail and so workflow suspends. So, when such suspended workflow is resumed that actually restarts the failed tasks in the run. I noticed, in 7.1, even though resuming does not create a new workflow_run_id, tasks that restarts when its parent workflow is resumed would create new entries in REP_TASK_INST_RUN. That might be for good reason, but I see that of not much help rather misleading as there is no column that distinguishes task restarts (start_time of task can give that info, but that's not a good candidate).
Moreover, Informatica 7.1 behaves badly in maintaining information in those records - if a task is failed, say 3 times, when resumed multiple times, and finally succeeded in 4th attempt, then all the 4 records of that task run would get updated with last run information (except start_time that I identified) - end_time, error_code etc...and I would say this is completely misleading. Similar behaviour can be noticed in other tables/views that stores the task level run time information like REP_SESS_LOG (OPB_SESS_LOG).
If you run this below query on 7.1 repository you would notice some records being fetched (provided there was atleast one attempt of resuming a suspended workflow)
select workflow_run_id, instance_id, count(*) from infav71.rep_task_inst_run group by workflow_run_id, instance_id having count(*) > 1Even more dangerous part is with the views that joins OPB_TASK_INST_RUN and OPB_SESS_LOG tables. As I said, there is no good candidate in those tables to identify the multiple task (or instance to be precise) runs when suspended workflow is resumed, joining these 2 tables would make cartesian product - means 4 entries in both these 2 tables would return 8 records - that's a flaw, and you can notice that in 7.1.
select * from infa71.OPB_TASK_INST_RUN where INSTANCE_ID = 18738 and WORKFLOW_RUN_ID = 7113806; SUBJECT_ID WORKFLOW_ID WORKFLOW_RUN_ID WORKLET_RUN_ID CHILD_RUN_ID INSTANCE_ID INSTANCE_NAME TASK_NAME TASK_ID TASK_TYPE START_TIME END_TIME RUN_ERR_CODE RUN_ERR_MSG RUN_STATUS_CODE RUN_MODE VERSION_NUMBER SERVER_ID SERVER_NAME 48 13707 7113806 7113823 0 18738 s_m_test s_m_test 20461 68 8/24/2009 2:00 8/24/2009 2:00 0 1 1 1 1 TEST_SRVR 48 13707 7113806 7113823 0 18738 s_m_test s_m_test 20461 68 8/24/2009 1:47 8/24/2009 2:00 0 1 1 1 1 TEST_SRVR 48 13707 7113806 7113823 0 18738 s_m_test s_m_test 20461 68 8/24/2009 1:14 8/24/2009 2:00 0 1 1 1 1 TEST_SRVR 48 13707 7113806 7113823 0 18738 s_m_test s_m_test 20461 68 8/24/2009 0:52 8/24/2009 2:00 0 1 1 1 1 TEST_SRVR 48 13707 7113806 7113823 0 18738 s_m_test s_m_test 20461 68 8/24/2009 0:17 8/24/2009 2:00 0 1 1 1 1 TEST_SRVR 48 13707 7113806 7113823 0 18738 s_m_test s_m_test 20461 68 8/24/2009 0:02 8/24/2009 2:00 0 1 1 1 1 TEST_SRVR
If you look at the above result only start_time is differing, and values of older runs are updated to last run values (error_code, end_time etc... though they have different values from run to run)
Looks like it's fixed in 8.6 - I did not test in version between 7.1 and 8.6 though. In 8.6 however number of resuming of a suspended workflow may be, a failed task instance would have only one run per workflow_run_id. This is much better, rather misleading with more information. if you run the first group by query in your 8.6 repository, you should not be getting any records at all.
select workflow_run_id, instance_id, count(*) from infav88.rep_task_inst_run group by workflow_run_id, instance_id having count(*) > 1 0 row(s) retrieved
Hope that helps.
I appreciate your comments... Thanks!
Karteek
I never had a positive opinion on making resolutions on specific occasions like new year and birthday, neither a negative opinion too – I was just neutral, never thought about that concept at all. I want to try that now…that’s a positive wave and powerful I think. Would be even more powerful when your resolution is spread among the people around you. And especially if you are open in your resolution in giving up some bad habit it will have tremendous impact - because people around you are watching even you want to take a chance :-) - that’s ok, that’s not bad.
Today is my birthday, and this is the first time in my life I want to make couple of resolutions – related to my time and sleep.
I haven’t been very good at these two – I need to improve my time management skills and I need to try to fix my sleeping hours.
I don’t have a specific strategy right now to manage my time…but I need to plan something now at least. These days I’m really feeling that I haven’t been up to in my productivity though I’ve been very busy working on several pieces simultaneously. I know I can do even better, if there is a plan in place, and if I adhere to that. This is something VERY serious that everyone should look into when they are finding the reduced productivity with increased time effort. Varun, when he came to Hyderabad recently, was talking about Steven Covey’s time management stuff (First Things First) – a framework to prioritize your work in a 2x2 matrix – I’ve this below image from wikipedia page. That’s a good concept – many people knew about the truth he explained but that is a spark only when someone reminds or talks about that. From the same page few more words…”His quadrant 2 has the items that are non-urgent but important. These are the ones he believes we are likely to neglect; but, should focus on to achieve effectiveness.”
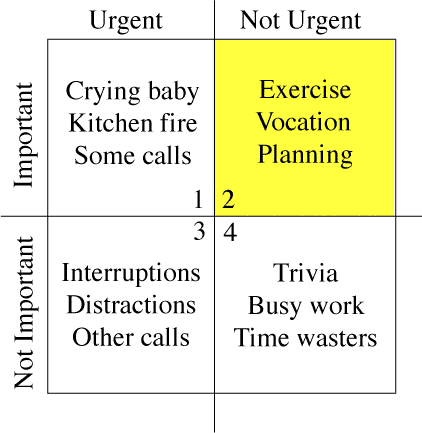
- I see my SAS certification fits into Q2 perfectly. That’s one of my important goals in the near future, and however that’s not urgent for me. Many things come to Q1 only if you don’t accomplish then in Q1. But the important thing realizing Q2 things is relatively difficult, and even more difficult to make that true. That’s your strategic area, and you just have to be committed.
- Right now I don’t have any day-planner – I’m thinking of having it one – at least some notes on paper/book/calendar – anywhere. I can improvise that as I use.
I think I can easily fix my sleeping timings. I know this is not fully in my hands everyday – my work at office sometimes forces me work late hours too. If I can handle Q1,3 and 4 tasks well, hopefully I can even control my working and learning hours very well. 6hours of good sleep (without any dreams :-) ) is sufficient for me. But on some days I even slept for over 8hours!! 8 hours sleep is of no use, seriously – I never felt restless when I had 6 hours of sleep, rather if I enjoyed the busy day. And if you maintain the consistency in the sleep time and number of hours that would be awesome – you are disciplined and by that you have much more potential than you used to have. I’m planning to go to sleep between 12:00 to 6:00 AM. 6 hours sleep id not new to me, but can I turn that into habit? Let me see how far I can make it.
Wish me best!! Those are my birthday wishes…
- K
Does it mean amazing Oracle-Solaris duo!!?? That's a good sign.
I wish Oracle will not damage MySQL - Open Source should live.
http://www.oracle.com/us/corporate/press/018363 Some interesting posts related to this $7.4 billion deal… http://www.infoworld.com/d/developer-world/what-if-oracle-bought-sun-microsystems-859 http://developers.slashdot.org/article.pl?sid=09/04/09/1819241&from=rss
FTP still continues to be part of many projects when there is a need to transfer the files across the machines. But the question is about its reliablility. It's very useful but unfortunately it's equally unreliable from programming perspective, I believe. Especially those who have some experience on Unix/Linux platform and have love towards $? (exit status of last issued command) would not feel good for FTP.
There are many ftp tools out there in the market that are exception sensitive, but we , including me, are still using the standard/default ftp client that comes with most Linux/Unix/Windows versions. That's not bad as long as there is a way to tune it in our way. In fact ftp does exceptionaly well in terms of speed , logging etc... - all it lacking is error handling. Irrespective of any success/failure of a command or even in the case of connectivity issues ftp always returns "success" ("0") as exit status. That's really annoying, because even a simple "ls" command handles this properly.
$ ls abc ls: abc: No such file or directory $ echo $? 1 $
"ls" command returned 1 (failed) as couldn't find a file called "abc". See the below similar attempt on ftp.
$ ftp -n 3.112.45.192<user karteek password > bye > E User karteek cannot log in. Login failed. $ echo $? 0 $
This is why I said - it's annoying. Login itself failed, but status is success. I tested, whatever the trash you issue in ftp console, final exit status of ftp is "0" that's success.
So, people have been adding thier own customization to ftp to validate the file transfer. Few of some known logics are like (assuming get command is used, instead put)...
Get all the data files along with and additional control file containing the file_name and size_in_bytes (or just sum of sizes of all files as single value) information. After FTP completion, validate the files in the local machine using the size value specified in control file.
- Using FTP status codes. FTP generates status codes upon each command execution, including some additional codes in its life cycle. Status codes can be grepped from ftp log file and execution can be validated. First 3 digits i nthe log file gives the status code. Note that, a simple grep (grep "^XYZ") is not reliable, because when a file is transferred, bytes send or received is also logged with number of bytes at the start of status line). So, we should filter out "bytes sent" (in case of put) and "bytes received" first and then grep the status codes. FTP status codes is listed in the below link. http://www.ftpplanet.com/ftpresources/ftp_codes.htm
- You can even read the number of "bytes received" that's being logged for each file transfer in the ftp log file (like I said in above point). Sum up all those values and compare that with the local files' size. This approach is better than 1st one, because first approch requires an explicit aggrement needs to be made between files sender and receiver that a control file is generated each time.
However both methods have one common problem. File sizes may not be same on both remote as well as local machine, especially when the transfer mode is ascii. Suppose, if a file pulled (get) from a windows machine to a unix machine or vice versa, carriage returns are removed or appended to every end of line (because eod-of-line diffrence between windows, \r\n, and linux ,\n). So, if a file is pulled from windows to unix then its local file size would be less than remote file. And moreover, in such ascii PC to Linux transfers warnings like " bare linefeeds received in ASCII mode" are also very common which again would have impact on size.
So, I tried another approach, and it seemd to be doing well as of now.- Start FTP and prompt off
- Get the files to local machine (say, using mget)
- Create a new file on local machine with file listing of remote directory (using mls or mdir).
- Disconnect FTP
- No need to try $? - that's mere waste!
- Calculate sum of sizes of all the files present in additionally created file
- Grep the ftp log file for "bytes received in" and find total of bytes
- Compare above 2 values, and they should be same for a successfull file transfer
With this same I've this below script...at least this helps as a foundation or creates some line of thought
###################################################################
# Scrit Name: ValidateFTP.ksh
# by Karteek Yelampally, 03/13/2009
###################################################################
# Functiono to validate the FTP transfer
Validate_ftp(){
# Arguments to the current function
FTP_LOG=$1
FILE_LST_R=$2 # Validate the ftp transfer
if [ -f ${FILE_LST_R} ]; then # Listing file exists
if [ ! -s ${FILE_LST_R} ]; then # Listing file exists but with zero size
echo "No files found on the remote machine with the specified pattern(s) ${FILE_PAT}" >> ${FTP_LOG} return 0
fi
else # Listing file does not exist
echo "Fatal ERROR: File transfer failed. Failure in getting the file listing on remote machine." >> ${FTP_LOG}
return 1
fi
echo >> ${FTP_LOG}
echo "File listing on the remote machine..." >> ${FTP_LOG}
cat ${FILE_LST_R} >> ${FTP_LOG} # Read the ftp log file and calculate number of bytes sent by ftp
FILE_SIZE_L=`grep "bytes received in" ${FTP_LOG} awk '{x+=$1}END{print x}'` # Read the remote file listing and calculate the total files' size on the remote machine
FILE_SIZE_R=`awk '{x+=$3} END{print x}' ${FILE_LST_R}` # Check if the remote files' size and local files' size is equal or not
if [ "${FILE_SIZE_L}" -eq "${FILE_SIZE_R}" ]; then
echo "File transfer completed successfully. [${FILE_SIZE_L}] bytes transferred." >> ${FTP_LOG}
else
echo "File transfer failed. Size on remote machine [${FILE_SIZE_R}] does not match with Bytes received [${FILE_SIZE_L}]." >> ${FTP_LOG}
return 1
fi
return 0
}
# Start scipt
FTP_HOST=3.1.45.192
FTP_USER=FTP_Security
FTP_PWD=Zz62BaTs
TGT_HOME=/export/home/karteek/SrcFiles
FTP_LOG=/export/home/karteek/Logs/`basename $0 .sh`_`date +"%Y%m%d%H%M%S"`.log
FILE_LST_R=/export/home/karteek/Temp/list_of_remote_file$$.tmp
echo "Log file is ${FTP_LOG}" FILE_PAT="*DAT" FTP_REMOTE_DIR="/ftp/vendor"
FTP_LOCAL_DIR=${TGT_HOME}/received_files echo "FTP Started"
ftp -n -v ${FTP_HOST} <&1 >> ${FTP_LOG}
user ${FTP_USER} ${FTP_PWD}
cd ${FTP_REMOTE_DIR}
lcd ${FTP_LOCAL_DIR}
prompt
ascii
mget ${FILE_PAT}
mdir ${FILE_PAT} ${FILE_LST_R}
bye
EOFtp
echo "FTP Finished"
Validate_ftp "${FTP_LOG}" "${FILE_LST_R}"
echo "FTP Status is " $?
###################################################################"mdir ${FILE_PAT} ${FILE_LST_R}" in the ftp commands creates the file, ${FILE_LST_R}, with remote file listing (having the pattern ${FILE_PAT}) on to local machine.
Let me your comments please. I would like to share your thoughts.
- Karteek
Sometimes we find ora-01410 as misleading. Couple of possible error cause scenarios are explained here... SQL> select * from dual where rowid='musings not allowed here'; select * from dual where rowid='musings not allowed here' *ERROR at line 1: ORA-01410: invalid ROWID I think , this error is probably much straighforward - you asked for some rowid which is actually invalid, by common sense, and Oracle repoted the same. But, we also sometimes see this error, even we don't reference to rowid psedo column - a typical select statement may very likely throw this error. I understood it due to Read Consistency. Even if it may sound strange, following explaination hopefully unveils the fact. Assume a session running a long running query that uses an index that gets rebuilt by another session. Indexes have some iteresting feature when it comes to rebuilding. While rebuilding, Oracle doesn't actually overwrite the inndex while it rebuilds, but it creates a fresh copy of index, and when new copy is ready to serve, it replaces the existing one. This approach improves the availability of the table quite effectively. Same is the reason why an index rebuild requires the the space atleast double the size of the index. Having said that, a long running query that started with using old copy of index, may later start using new copy while it still runs (because other index rebuild sessoin rebuilt/replaced the old copy). So, rowids fetched by the query at the begining (pointing to old index) are obsolete now as they are no longer valid. Hence the invalid rowid error. We can't expect the same read consistency that we get from transaction/DML operations. There are no invalid data or lost data as long as there is enough undo segment. Oracle reads though the undo segments for read consistent data. But in case of rebuild, it is DDL and it's lost forever, so we can't expect Oracle to do read consistency here as well. So, I think, read consistency with DDL is the responsibility of application rather than Oracle. Hope it helps! - Karteek
When to use one-to-one tables: I think it's been less talked about, as people talked about complex theories all the time. I've an excerpt from HeadFirst SQL, slightly edited, to explain the scenarios that may well suggest 1-1 relation split while you design a relational model.
Actually we won’t use one-to-one tables all that often. There are only a few reasons why you might connect your tables in one-to-one relationship. It generally makes more sense to leave your one-to-one data in your main table, but there are a few advantages you can get from pulling those columns out at times:
- Pulling the data out may allow to write faster queries. For example, if most of the time you need to query the SSN number and not much else, you could query just the smaller table.
- If you have a column containing values you don’t yet know, you can isolate it and avoid NULL values in your main table.
- You may wish to make some of your data less accessible. Isolating it can allow you to restrict access to it. For example, if you have table of employees, you might want to keep their salary information out of the main table.
- If you have a larger piece of data, a BLOB type for example, you may want that larger data in separate table.
- I’ve seen one scenario personally. When there is limitation on maximum number of columns that a table can have, you can split a single table into multiple, and establish a one-to-one relationship between them.
Happy reading...
