Estimate the Efficiency using Explain Plan and analyze the Perf using TKPROF
0 comments Posted by Karteek at 12/06/2006Use EXPLAIN PLAN and TKPROF To Tune Your Applications
http://www.dbspecialists.com/presentations/use_explain.html
Examples that Roger Schrag (author) used for Explain Plan are good and well enough to interpret the Explain plan output. Here I am putting (pasting) few good points that he covered in that paper. But, I would suggest to read the paper (I have got 25 pages with typical ms word settings).
- A nested loops join operation always takes two inputs: For every row coming from the first input, the second input is executed once to find matching rows. A hash join operation also takes two inputs: The second input is read completely once and used to build a hash. For each row coming from the first input, one probe is performed against this hash. Sorting operations, meanwhile, take in one input. When the entire input has been read, the rows are sorted and output in the desired order. The merge join operation always takes two inputs, with the prerequisite that each input has already been sorted on the join column or columns. The merge join operation reads both inputs in their entirety at one time and outputs the results of the join. Merge joins and hash joins are usually more efficient than nested loops joins when remote tables are involved, because these types of joins will almost always involve fewer network roundtrips.

- Oracle is able to perform simple filtering operations while performing a full table scan. Therefore, a separate filter operation will not appear in the execution plan when Oracle performs a full table scan and throws out rows that don’t satisfy a WHERE clause. Filter operations with one input commonly appear in queries with view operations or HAVING clauses, while filter operations with multiple inputs will appear in queries with EXISTS clauses.
- An important note about execution plans and subqueries: When a SQL statement involves subqueries, Oracle tries to merge the subquery into the main statement by using a join. If this is not feasible and the subquery does not have any dependencies or references to the main query, then Oracle will treat the subquery as a completely separate statement from the standpoint of developing an execution plan—almost as if two separate SQL statements were sent to the database server. When you generate an execution plan for a statement that includes a fully autonomous subquery, the execution plan may not include the operations for the subquery. In this situation, you need to generate an execution plan for the subquery separately.
- Karteek
One of the good collections that I could able to gather is abt the evaluation of Shell command. Most of this extraction is directly from Classic Shell Scriptin-Oreilly. It's just like a tutorial, pls bear with me, I don't have much time to elaborate it. I think this is good enough. Though it is a fundamental concept, I don't prefer someone who is new to shell env to read this post. Unnecessarily it will create chaos. Ok....let us start.... Each line that the shell reads from the standard input or a script is called a pipeline; it contains one or more commands separated by zero or more pipe characters (). (Actually, several special symbols separate individual commands: semicolon, ;, pipe, , ampersand, &, logical AND, &&, and logical OR, .) For each pipeline it reads, the shell breaks it up into commands, sets up the I/O for the pipeline, and then does the following for each command, in the order shown: 1) Splits the command into tokens that are separated by the fixed set of metacharacters: space, tab, newline, ;, (, ), <, >, , and &. Types of tokens include words, keywords, I/O redirectors, and semicolons. It's a subtle point, but variable, command, and arithmetic substitution can be performed while the shell is doing token recognition. 2) Checks the first token of each command to see if it is a keyword with no quotes or backslashes. If it's an opening keyword (if and other control-structure openers, {, or (), then the command is actually a compound command. The shell sets things up internally for the compound command, reads the next command, and starts the process again. If the keyword isn't a compound command opener (e.g., is a control-structure middle like then, else, or do, an end like fi or done, or a logical operator), the shell signals a syntax error. 3) Checks the first word of each command against the list of aliases. If a match is found, it substitutes the alias's definition and goes back to step 1; otherwise it goes on to step 4. The return to step 1 allows aliases for keywords to be defined: e.g., alias aslongas=while or alias procedure=function. Note that the shell does not do recursive alias expansion: instead, it recognizes when an alias expands to the same command, and stops the potential recursion. Alias expansion can be inhibited by quoting any part of the word to be protected. 4) Substitutes the user's home directory ($HOME) for the tilde character (~) if it is at the beginning of a word. Substitutes user's home directory for ~user. Tilde substitution (in shells that support it) occurs at the following places:
- As the first unquoted character of a word on the command line
- After the = in a variable assignment and after any : in the value of a variable assignment
- For the word part of variable substitutions of the form ${variable op word}
5) Performs parameter (variable) substitution for any expression that starts with a dollar sign ($).
6) Does command substitution for any expression of the form $(string) or `string`. 7) Evaluates arithmetic expressions of the form $((string)). 8) Takes the parts of the line that resulted from parameter, command, and arithmetic substitution and splits them into words again. This time it uses the characters in $IFS as delimiters instead of the set of metacharacters in step 1. Normally, successive multiple input occurrences of characters in IFS act as a single delimiter, which is what you would expect. This is true only for whitespace characters, such as space and tab. For nonwhitespace characters, this is not true. For example, when reading the colon-separated fields of /etc/passwd, two successive colons delimit an empty field: while IFS=: read name passwd uid gid fullname homedir shell do ... done < /etc/passwd
After I came back from Vijayawada meeting my friends, yesterday, I started surfing aimlessly - truly aimless. But it was good time that I got to know about some interesting feature in Oracle. I never thought of this feature. Of course there was a reason for not thiniking about this feature, as Oracle already had a similar* feature.
Last week my client had sent a request tp delete few records based on columnA, columnB combination. It must be very simple right?- just a simple delete statement. But, they sent around 200 such combination values. How do you do?. Do you execute Delete statement for 200 times?. I think it is time wasting process. Definitely it would have been naive implementation had I used Delete statement for 200 times :). As a simple method, I created a temporary table and loaded that table with the data that my client had provided. That's all, now both Main data and the Reference data are in database. Now write a single Delete stmt to delete the records from the Main table using the data in the Reference table. But, only question is how to load the external data into a Database table? - Answer is Oracle's sql loader tool. For loading the data from flat files into a table, we need to setup some environment variables(oracle_home, tns_admin...), need to create Control file.
Control File(demo.ctl):
LOAD DATA
INFILE *
INTO TABLE Finally, one interesting feature in SQL Loader...
Use CONCATENATE when you want SQL*Loader to always combine the same number of physical records to form one logical record. In the following example, integer specifies the number of physical records to combine.
CONCATENATE integer
Use CONTINUEIF if the number of physical records to be continued varies. The
parameter CONTINUEIF is followed by a condition that is evaluated for each
physical record, as it is read.
CONTINUEIF THIS NEXT LAST condition
Assume that you have physical records 14 bytes long and that a period represents a
space:
%%aaaaaaaa....
%%bbbbbbbb......
cccccccc....
%%dddddddddd..
%%eeeeeeeeee....
ffffffffff..
CONTINUEIF THIS (1:2) = '%%'
Therefore, the logical records are assembled as follows:
aaaaaaaa....bbbbbbbb....cccccccc....
dddddddddd..eeeeeeeeee..ffffffffff..
(http://dba-services.berkeley.edu/docs/oracle/manual-9iR2/server.920/a96652/ch05.htm)
That's all for this post. Catch u here again...
-Karteeek
If u r already much comfortable with access modifiers, I think u need not to scroll down.
Here is the summary of access specifiers...
Access level modifiers determine whether other classes can use a particular field or invoke a particular method. There are two levels of access control:
- At the top level-public, or package-private (no explicit modifier). - especially, at the Class level access modifier.
- At the member level-public, private, protected, or package-private (no explicit modifier).
At the top level..., a class may be declared with the modifier public, in which case that class is visible to all classes everywhere. If a class has no modifier (the default, also known as package-private), it is visible only within its own package.
package mypack; private class HelloWorldParent { //is invalid. This should be public or default public HelloWorldParent(){} } -- I was not aware of this point earlier. Only this point made me to post this in my blog.
At the member level, you can also use the public modifier or no modifier (package-private) just as with top-level classes, and with the same meaning. For members, there are two additional access modifiers: private and protected. The private modifier specifies that the member can only be accessed in its own class. The protected modifier specifies that the member can only be accessed within its own package (as with package-private) and, in addition, by a subclass of its class in another package.
The following table shows the access to members permitted by each modifier. You can find this typical information in any Java fundamental books.
Access Levels
Modifier Class Package Subclass World
public Y Y Y Y
protected Y Y Y N
default Y Y N N
private Y N N N
Hope this material would be helpful to u.
I've been finding difficulty in formatting the text and graphics in my blog. Hope I will find the solution soon...
-Karteeek
I got the following from "I am feeling Lucky" for "Difference between Regular Cursors and Ref Cursors" search string :)). Please don't think like "wht is the necessity in having a post on this, if it is already the first hit from Google". A big NO. It's extraction from several such search good hits. Once again, thanks to Google, making lives easy. ok, let us go down. These are Toms words in asktom... Technically, under the covers, at the most "basic level", they are the same. A "normal" plsql cursor is static in defintion. Ref cursors may be dynamically opened or opened based on logic. Look at the following code Declare type rc is ref cursor; cursor c is select * from dual; l_cursor rc; -- Referential cursor declaration begin if ( to_char(sysdate,'dd') = 30 ) then open l_cursor for 'select * from emp'; -- l_cursor can be for #select * from emp# elsif ( to_char(sysdate,'dd') = 29 ) then open l_cursor for select * from dept; -- l_cursor can be for #select * from dept# else open l_cursor for select * from dual; -- l_cursor can even be for #select * from dual# end if; open c; -- but cursor C is always for # select * from dual # end; / Given that block of code -- you see perhaps the most "salient" difference -- no matter how many times you run that block -- cursor C will always be select * from dual. The ref cursor can be anything. Another difference is, a ref cursor can be returned to a client. a plsql "cursor cursor" cannot be returned to a client. -- We are using this feature of Ref cursor in our project. We r using Pro C as a client to Oracle DB. From Pro C, we call the stored procedure which would return a ref cursor to the calling environment. Another difference is, a cursor can be global -- a ref cursor cannot (you cannot define them OUTSIDE of a procedure / function) Another difference is, a ref cursor can be passed from subroutine to subroutine, a cursor cannot be. -- U can find an example on this if u scroll down Another difference is that static sql (not using a ref cursor) is much more efficient than using ref cursors and that use of ref cursors should be limited to - returning result sets to clients - when there is NO other efficient/effective means of achieving the goal that is, you want to use static SQL (with implicit cursors really) first and use a ref cursor only when you absolutely have to. Ex: A ref cursor, passed as a parameter... CREATE OR REPLACE PROCEDURE pass_ref_cur(p_cursor SYS_REFCURSOR) IS TYPE array_t IS TABLE OF VARCHAR2(4000) INDEX BY BINARY_INTEGER; rec_array array_t; BEGIN FETCH p_cursor BULK COLLECT INTO rec_array; FOR i IN rec_array.FIRST .. rec_array.LAST LOOP dbms_output.put_line(rec_array(i)); END LOOP; END pass_ref_cur; / DECLARE rec_array SYS_REFCURSOR; BEGIN OPEN rec_array FOR 'SELECT empname FROM employees'; pass_ref_cur(rec_array); CLOSE rec_array; END; / Here Ref Cursor is weakly typed. For strongly typed declaration we can use TYPE return_cur IS REF CURSOR RETURN all_tables%ROWTYPE; Hold on a moment, wht is the diff b/w Strong and Weakly typed cursor?. Structure of the ref cursor is known by the compiler at compile time. create or replace package my_pkg as type strong is ref cursor return emp%rowtype; type weak is ref cursor; end; / Package created. STRONG's structure -- the columns, their datatypes, their lengths, everything -- are well known at compile time. It can only be used to return rows that look exactly like the EMP table (doesn't have to be from the EMP table -- just must be the same STRUCTURE). WEAK's structure -- not known. It could be used with: open a_weak_one for select * from dual; or open a_weak_one for select * from dept; Its structure is NOT known at compile time and may actually change from use to use. Here I have question for u.... There will not be a significant performance difference between Strong and Weakly typed ref cursors. Then why should I go for Strongly typed cursors. Think again, before scrolling down further. Why should one declare a cursor variable in a complex way, mentioning the return type also?. Strongly typed ones can be "described". These are "easier for a tool like forms or powerbuilder to layout a screen to hold the results". I should have posted this Stong and Weak ref cursors in a seperate thread. I will do it, once I get more information on these. Catch u here again -- Karteeek
Following would not add any value to you if you are already working as a Java developer. Think once before scrolling down. So u've decided to go down. Ok, let us go. How do u initialize an instance variable? - studpid question, right? yes, it is. we do it in constructor also, we can directly initiaze while declaring. Same question, but it is regarding initialization of Class member. plz don't say I use the constructor for this also. Ofcourse u won't tell, bcoz Class variable doesn't belong to any of the instances.(contructor would be called while instantiating a Class) Hey, I can directly assign the Class variable using binary operators like =, += etc while it's declaration. Same is valid for ternary operator(?:) also. Yes, u can provide an initial value for a class or an instance member variable in its declaration like public class BedAndBreakfast { //initialize to 10 public static final int MAX_CAPACITY = 10; //initialize to false private boolean full = false; } But, don't u think it has some limitations. If u don't think plz try to think abt these questions.
- How can I call a method or use a stmt(if-else, case etc) to assign the returned value.
- How can JVM handle the exception that is raised by initialization expression or by method called .
These are some basic java stuff - very basic. Some definitions also. Hey, plz don't get scared. I personally feel that these things should not be ignored. Most of us use these concepts extensively but not sure wht exactly they are meant for and how exactly they work. At some points, u can practice RC - just read them.
- A class--the basic building block of an object-oriented language such as Java--is a template that describes the data and behavior associated with instances of that class. The data associated with a class or object is stored in variables; the behavior associated with a class or object is implemented with methods.
- When the System class is loaded into the application, it instantiates PrintStream and assigns the new PrintStream object to the out class variable. Now that you have an instance of a class, you can call one of its instance methods:
System.out.println("Hello World!");
- The argument to java (while running the program) is the name of the class that you want to use, not the filename.
- final int aFinalVar = 0; You may, if necessary, defer initialization of a final local variable. Simply declare the local variable and initialize it later, as follows. final int blankfinal; . . . blankfinal = 0; A final local variable that has been declared but not yet initialized is called a blank final. Again, once a final local variable has been initialized, it cannot be set again.
- The unlabeled form of the break statement is used to terminate the innermost switch, for, while, or do-while statement; the labeled form terminates an outer statement, which is identified by the label specified in the break statement. Similar is the case with both labelled and unlabelled continue stmt which skips the current iteration.
- public Rectangle(int w, int h) {
this(new Point(0, 0), w, h);
} - I haven't ever used this.
The most common reason for using this is that a member variable is hidden by an argument to the method or the constructor.
- String — for immutable (unchanging) data. StringBuffer — for storing and manipulating mutable data. This class is safe for use in a multi-threaded environment. StringBuilder — A faster, drop-in replacement for StringBuffer, designed for use by a single thread only.
- If you are passing a primitive data type (such as a char) into a method that expects a wrapper object (such as a Character) the Java compiler automatically converts the type for you. This feature is called autoboxing or unboxing if the conversion goes the other way.
- private access specifier in a constructor's declaration Only this class can use this constructor. Making a constructor private, in essence, makes the class final — the class can't be subclassed, except from within. If all constructors within a class are private, the class might contain public class methods (called factory methods) that create and initialize an instance of this class. Other classes can use the factory methods to create an instance of this class.
- Variable number of arguments can also be passed to a method(introduced in J2SE 5.0). public static Polygon polygonFrom(Point... listOfPoints) { ... } for example, the printf method: public PrintStream printf(String format, Object... args) can then be called like this: System.out.printf("%s: %d, %s%n", name, idnum, address);
Now suppose that you have a method declared to return a Number: public Number returnANumber() {
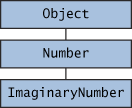 ...
}
The returnANumber method can return an ImaginaryNumber but not an Object. ImaginaryNumber is a Number because it's a subclass of Number. However, an Object is not necessarily a Number — it could be a String or another type.
You can override a method and define it to return a subclass of the original method, like this:
public ImaginaryNumber returnANumber() {
...
}
This technique, called covariant return type (introduced in release 5.0), means that the return type is allowed to vary in the same direction as the subclass. You also can use interface names as return types. In this case, the object returned must implement the specified interface..
...
}
The returnANumber method can return an ImaginaryNumber but not an Object. ImaginaryNumber is a Number because it's a subclass of Number. However, an Object is not necessarily a Number — it could be a String or another type.
You can override a method and define it to return a subclass of the original method, like this:
public ImaginaryNumber returnANumber() {
...
}
This technique, called covariant return type (introduced in release 5.0), means that the return type is allowed to vary in the same direction as the subclass. You also can use interface names as return types. In this case, the object returned must implement the specified interface..

- The overriding method has the same name, number and type of arguments, and return value as the method it overrides. (In fact the return type of a subclass can be a subclass of the return type of its superclass.) The overriding method can have a different throws clause as long as it doesn't specify any types not specified by the throws clause in the overridden method. Also, the access specifier for the overriding method can allow more but not less access than the overridden method. For example, a protected method in the superclass can be made public but not private.
- If a subclass defines a class method with the same signature as a class method in the superclass, the method in the subclass hides the one in the superclass. The distinction between hiding and overriding has important implications. For class methods, the runtime system invokes the method defined in the compile-time type of the reference on which the method is called. For instance methods, the runtime system invokes the method defined in the runtime type of the reference on which the method is called.
Animal super class public class Animal {
public static void hide() {
System.out.format("The hide method in Animal.%n");
} public void override() {
System.out.format("The override method in Animal.%n");
}
}
The second class, a subclass of Animal, is called Cat:
public class Cat extends Animal {
public static void hide() {
System.out.format("The hide method in Cat.%n");
}
public void override() {
System.out.format("The override method in Cat.%n");
} public static void main(String[] args) {
Cat myCat = new Cat();
Animal myAnimal = myCat;
//myAnimal.hide(); //BAD STYLE
Animal.hide(); //Better! Cat.hide();
myAnimal.override();
}
}
The hide method in Animal --- decided at compile time
The hide method in Cat --- decided at compile time
The override method in Cat --- decided at run time (at compile time it is Animal class' override(), but at runtime it changed to Cat classes' override() method).
Defining a Method with the Same Signature as a Superclass's Method:
An instance method cannot override a static method and vice versa. Superclass Instance Method Superclass Static Method
Instance Method Overrides (return type must be a Generates a compile-time error
subtype of the return type of the
superclass's method) Static Method Generates a compile-time error Hides
--Karteeek
For the last couple of weeks we've been facing 750 performance issue in our project. 75o application takes customer's response and stores them in DB. (740 application offers products to the customers). Today, Devyani and Ajoy from GECF America's DBA team have asked us to run a performance test so that they can monitor it. I started with 100K requests which caused router to get down. Router is mediator b/w our database and java TestHarness application. As load is more(100K), TestHarness creates more threads(>120), which router couldn't handle. We've decided to go with 5K offers. DBA suggested us to change cache value of SEQUENCE from 20 to 1500. Pankaj did that. He also sent me the SQL stmt to do that. ALTER SEQUENCE RESPONSE_SEQ CACHE 1500 We also set the DEBUBBING MODE ON in our oracle scripts. Oracle scripts were developed in such a way that if debug mode is ON, only then every activity in DB level is logged. I started test with 5K with these settings. This time performance is good. % of response time that crossed 100ms has come down from 98% to 12%. Very good change. Then Ajoy said, "In RAC environment, when multiple instances try to access the same sequence, there could be a contention". Then Pankaj suggested another round of test with 100K with DEBUG MODE OFF. This time, again performance has gone down to 98%!!!!!!!!. Unable to guess the route cause. I left the office after sharing test procedure with Pankaj, as it is already 9.00 PM. Will come back with a post on the same thread, once this performance issue is resolved. I think, here, all the possible usages of SEQUENCE is explained http://www.psoug.org/reference/sequences.html Interesting point that I found on this page is, "How to reset a sequence to particular number?(or Reset sequence to zero)". For this, if the current value of sequence is 12, then alter the sequence to increment by -12 and execute seq.nextval stmt. That's it, current value of sequence would become zero. CREATE SEQUENCE seq; SELECT seq.NEXTVAL FROM dual; SELECT seq.NEXTVAL FROM dual; SELECT seq.NEXTVAL FROM dual; COLUMN S new_val inc; -- latest value in "S" column will be placed in "inc" variable(here inc = 3) . To put the same in other way, this stmt will create a substitution variable "inc", whose value will be automatically replaced by the new value of column "S". SELECT seq.NEXTVAL S FROM dual; -- value of S is 4, therefore inc = 4 ALTER SEQUENCE seq INCREMENT BY -&inc MINVALUE 0; -- inc will be automatically replaced with 4 SELECT seq.NEXTVAL S FROM dual; -- returns zero ALTER SEQUENCE seq increment by 1; -- reverting the seq increment value SELECT seq.NEXTVAL FROM dual; Earlier, I was thinking that is there any option to reset the sequence val directly. I think NO. No problem, above method is pretty well, I think. Get back to U - Karteeek
As part my project's development process, I am developing two procedures, one for creating index and the other for dropping it. In our DB, we already have a table with primary key constraint on a set of columns, say (a,b,c). I created the procedures. not a great work. very simple, right?, just creating index. I've done that. Now, time to test them. I started my testing with DROP procedure. As per my guess it should fail with error message like no index exists... Yes it failed, but error is different. Some thing like cannot drop index used for enforcement of unique/primary key. STRANGE, never saw such message. I had a marathon on............ on what?........wht else, on Google. I collected some information regarding this problem. Thanks to Tom again. Here I tried to explain the things in a stupid way, I have a table student(sid, sname) Added PK constraint alter table student add constraint pk_student primary key(sid); Create Unique Index ro achieve performance create unique index idx_student on student(sid); now if I try to drop the index... drop index idx_student ORA-02429: cannot drop index used for enforcement of unique/primary key Solution: first drop or disable the constraint and then drop index Same point, trying to put more in detail... If I create a table with primary or uniuqe constraint then it will automatically create a Unique index but nor vice versa. SQL> CREATE TABLE IDX_TABLE(IDNO NUMBER (4)); Table created. After inserting values... SQL> SELECT * FROM IDX_TABLE; IDNO ---------- 11 12 13 14 15 creating primary key constraint... SQL> ALTER TABLE IDX_TABLE ADD CONSTRAINT PK_IDX_TABLE PRIMARY KEY(IDNO); Table altered. SQL> SELECT CONSTRAINT_NAME FROM USER_CONSTRAINTS WHERE TABLE_NAME = 'IDX_TABLE'; CONSTRAINT_NAME ------------------------------ PK_IDX_TABLE SQL> SELECT INDEX_NAME FROM USER_INDEXES WHERE TABLE_NAME = 'IDX_TABLE'; INDEX_NAME ------------------------------ PK_IDX_TABLE So, if I try to create index on IDX_TABLE on the same set of columns it will throw an error. SQL> DROP INDEX PK_IDX_TABLE; DROP INDEX PK_IDX_TABLE * ERROR at line 1: ORA-02429: cannot drop index used for enforcement of unique/primary key When u try to create a Unique or Primary Key constraint...
- if index is not found(yes, not found here) and constraint is not deferrable(yes, not deferrable here), it creates unique index by default(so, created unique index)
- if not found(yes, not found here) and constraint is deferrable(NO, not deferrable here), it creates non-unique index by default
Here are some useful awk shell commands. Sivanarayana, my colleague has shared these with me. Some of these are interesting. # double space a file nawk '1;{print ""}' # double space a file which already has blank lines in it. Output file # should contain no more than one blank line between lines of text. # NOTE: On Unix systems, DOS lines which have only CRLF (\r\n) are # often treated as non-blank, and thus 'NF' alone will return TRUE. nawk 'NF{print $0 "\n"}' # triple space a file nawk '1;{print "\n"}' NUMBERING AND CALCULATIONS: # precede each line by its line number FOR THAT FILE (left alignment). # Using a tab (\t) instead of space will preserve margins. nawk '{print FNR "\t" $0}' files* # precede each line by its line number FOR ALL FILES TOGETHER, with tab. nawk '{print NR "\t" $0}' files* # number each line of a file (number on left, right-aligned) # Double the percent signs if typing from the DOS command prompt. nawk '{printf("%5d : %s\n", NR,$0)}' # number each line of file, but only print numbers if line is not blank # Remember caveats about Unix treatment of \r (mentioned above) nawk 'NF{$0=++a " :" $0};{print}' nawk '{print (NF? ++a " :" :"") $0}' # count lines (emulates "wc -l") awk 'END{print NR}' # print the sums of the fields of every line awk '{s=0; for (i=1; i<=NF; i++) s=s+$i; print s}' # add all fields in all lines and print the sum awk '{for (i=1; i<=NF; i++) s=s+$i}; END{print s}' # print every line after replacing each field with its absolute value awk '{for (i=1; i<=NF; i++) if ($i < 0) $i = -$i; print }' awk '{for (i=1; i<=NF; i++) $i = ($i < 0) ? -$i : $i; print }' # print the total number of fields ("words") in all lines awk '{ total = total + NF }; END {print total}' file # print the total number of lines that contain "Beth" awk '/Beth/{n++}; END {print n+0}' file # print the largest first field and the line that contains it # Intended for finding the longest string in field #1 awk '$1 > max {max=$1; maxline=$0}; END{ print max, maxline}' # print the number of fields in each line, followed by the line awk '{ print NF ":" $0 } ' # print the last field of each line awk '{ print $NF }' # print the last field of the last line awk '{ field = $NF }; END{ print field }' # print every line with more than 4 fields awk 'NF > 4' # print every line where the value of the last field is > 4 awk '$NF > 4' TEXT CONVERSION AND SUBSTITUTION: # IN UNIX ENVIRONMENT: convert DOS newlines (CR/LF) to Unix format awk '{sub(/\r$/,"");print}' # assumes EACH line ends with Ctrl-M # IN UNIX ENVIRONMENT: convert Unix newlines (LF) to DOS format awk '{sub(/$/,"\r");print} # IN DOS ENVIRONMENT: convert Unix newlines (LF) to DOS format awk 1 # IN DOS ENVIRONMENT: convert DOS newlines (CR/LF) to Unix format # Cannot be done with DOS versions of awk, other than gawk: gawk -v BINMODE="w" '1' infile >outfile # Use "tr" instead. tr -d \r <infile >outfile # GNU tr version 1.22 or higher # delete leading whitespace (spaces, tabs) from front of each line # aligns all text flush left awk '{sub(/^[ \t]+/, ""); print}' # delete trailing whitespace (spaces, tabs) from end of each line awk '{sub(/[ \t]+$/, "");print}' # delete BOTH leading and trailing whitespace from each line awk '{gsub(/^[ \t]+[ \t]+$/,"");print}' awk '{$1=$1;print}' # also removes extra space between fields # insert 5 blank spaces at beginning of each line (make page offset) awk '{sub(/^/, " ");print}' # align all text flush right on a 79-column width awk '{printf "%79s\n", $0}' file* # center all text on a 79-character width awk '{l=length();s=int((79-l)/2); printf "%"(s+l)"s\n",$0}' file* # substitute (find and replace) "foo" with "bar" on each line awk '{sub(/foo/,"bar");print}' # replaces only 1st instance gawk '{$0=gensub(/foo/,"bar",4);print}' # replaces only 4th instance awk '{gsub(/foo/,"bar");print}' # replaces ALL instances in a line # substitute "foo" with "bar" ONLY for lines which contain "baz" awk '/baz/{gsub(/foo/, "bar")};{print}' # substitute "foo" with "bar" EXCEPT for lines which contain "baz" awk '!/baz/{gsub(/foo/, "bar")};{print}' # change "scarlet" or "ruby" or "puce" to "red" awk '{gsub(/scarletrubypuce/, "red"); print}' # reverse order of lines (emulates "tac") awk '{a[i++]=$0} END {for (j=i-1; j>=0;) print a[j--] }' file* # if a line ends with a backslash, append the next line to it # (fails if there are multiple lines ending with backslash...) awk '/\\$/ {sub(/\\$/,""); getline t; print $0 t; next}; 1' file* # print and sort the login names of all users awk -F ":" '{ print $1 "sort" }' /etc/passwd # print the first 2 fields, in opposite order, of every line awk '{print $2, $1}' file # switch the first 2 fields of every line awk '{temp = $1; $1 = $2; $2 = temp}' file # print every line, deleting the second field of that line awk '{ $2 = ""; print }' # print in reverse order the fields of every line awk '{for (i=NF; i>0; i--) printf("%s ",i);printf ("\n")}' file # remove duplicate, consecutive lines (emulates "uniq") awk 'a !~ $0; {a=$0}' # remove duplicate, nonconsecutive lines awk '! a[$0]++' # most concise script awk '!($0 in a) {a[$0];print}' # most efficient script # concatenate every 5 lines of input, using a comma separator # between fields awk 'ORS=%NR%5?",":"\n"' file SELECTIVE PRINTING OF CERTAIN LINES: # print first 10 lines of file (emulates behavior of "head") awk 'NR < 11' # print first line of file (emulates "head -1") awk 'NR>1{exit};1' # print the last 2 lines of a file (emulates "tail -2") awk '{y=x "\n" $0; x=$0};END{print y}' # print the last line of a file (emulates "tail -1") awk 'END{print}' # print only lines which match regular expression (emulates "grep") awk '/regex/' # print only lines which do NOT match regex (emulates "grep -v") awk '!/regex/' # print the line immediately before a regex, but not the line # containing the regex awk '/regex/{print x};{x=$0}' awk '/regex/{print (x=="" ? "match on line 1" : x)};{x=$0}' # print the line immediately after a regex, but not the line # containing the regex awk '/regex/{getline;print}' # grep for AAA and BBB and CCC (in any order) awk '/AAA/; /BBB/; /CCC/' # grep for AAA and BBB and CCC (in that order) awk '/AAA.*BBB.*CCC/' # print only lines of 65 characters or longer awk 'length > 64' # print only lines of less than 65 characters awk 'length < 64' # print section of file from regular expression to end of file awk '/regex/,0' awk '/regex/,EOF' # print section of file based on line numbers (lines 8-12, inclusive) awk 'NR==8,NR==12' # print line number 52 awk 'NR==52' awk 'NR==52 {print;exit}' # more efficient on large files # print section of file between two regular expressions (inclusive) awk '/Iowa/,/Montana/' # case sensitive SELECTIVE DELETION OF CERTAIN LINES: # delete ALL blank lines from a file (same as "grep '.' ") awk NF awk '/./' DISTINCT PRODUCT CODES PRESENT DATA FILE awk '{ product[$5]} END{for (i in product ) print i }' File_Name.csv cut -f5 File_Name.csv sort -u -Karteek
VERY GENERIC CODE TO find the nth highest salary. SELECT LEVEL, MAX(SAL) FROM K_EMP WHERE LEVEL=N CONNECT BY PRIOR SAL > SAL GROUP BY LEVEL SELECT ' THE 'PARAMETER' OPTION IS NOT INSTALLED' FROM SYS.V_$OPTION WHERE VALUE <> 'TRUE'; We can simply check which features are not installed in the current DB. SELECT BANNER FROM SYS.V_$VERSION; To get the DB version details. DIFFERENCE BETWEEN & AND && "&" is used to create a temporary substitution variable that will prompt you for a value every time it is referenced. SQL> SELECT sal FROM emp WHERE ename LIKE '&NAME'; Enter value for name: SCOTT old 1: SELECT sal FROM emp WHERE ename LIKE '&NAME' new 1: SELECT sal FROM emp WHERE ename LIKE 'SCOTT' SAL ---------- 3000 SQL> / Enter value for name: SCOTT old 1: SELECT sal FROM emp WHERE ename LIKE '&NAME' new 1: SELECT sal FROM emp WHERE ename LIKE 'SCOTT' SAL ---------- 3000 "&&" is used to create a permanent substitution variable. Once you have entered a value (defined the variable) its value will used every time the variable is referenced. SQL> SELECT sal FROM emp WHERE ename LIKE '&&NAME'; Enter value for name: SCOTT old 1: SELECT sal FROM emp WHERE ename LIKE '&&NAME' new 1: SELECT sal FROM emp WHERE ename LIKE 'SCOTT' SAL ---------- 3000 SQL> / old 1: SELECT sal FROM emp WHERE ename LIKE '&&NAME' new 1: SELECT sal FROM emp WHERE ename LIKE 'SCOTT' SAL ---------- 3000 DEFINE also will have the similar functionality. SQL> DEFINE MYNAME='KARTEEK' SQL> DEFINE DEFINE _O_VERSION = "Oracle9i Enterprise Edition Release 9.2.0.5.0 - 64bit Production With the Partitioning, OLAP and Oracle Data Mining options DEFINE MYNAME = "KARTEEK" (CHAR) SQL> UNDEFINE MYNAME
Hey, I am getting fascinated towards SQL. REALLY!!!. What a query language!!. A real test for analytical and logical skills. I am planning to go deep into it. From today onwards u may find some posts on SQL and PL/SQL also.
PLAN_TABLE IS A VERY useful table that oracle has. Whenever a query is fired with explain plan option plan_table will be automatically updated with the execution plan.
Just truncate the table and execute your as…
explain plan for
I just have gone through arrays in AWK. These r not regular arrays that we see in many programming languages. Here I am putting some points that describe it briefly.
Arrays in awk are different: they are associative. This means that each array is a collection of pairs: an index, and its corresponding array element value:
Element 4 Value 30
Element 2 Value "foo"
Element 1 Value 8
Element 3 Value ""
Any number, or even a string, can be an index. For example, here is an array, which translates words from English into French:
Element "dog" Value "chien"
Element "cat" Value "chat"
Element "one" Value "un"
Element 1 Value "un"
The principal way of using an array is to refer to one of its elements. An array reference is an expression, which looks like this:
array[index]
For example, foo[4.3] is an expression for the element of array foo at index 4.3.
If you refer to an array element that has no recorded value, the value of the reference is "", the null string.You can find out if an element exists in an array at a certain index with the expression:
index in array
The expression has the value 1 (true) if array[index] exists, and 0 (false) if it does not exist.
Example:
This program sorts the lines by making an array using the line numbers as subscripts. It then prints out the lines in sorted order of their numbers.
{
if ($1 > max)
max = $1
arr[$1] = $0
}
END {
for (x = 1; x <= max; x++)
print arr[x]
}
The first rule keeps track of the largest line number seen so far; it also stores each line into the array arr, at an index that is the line's number.
The second rule runs after all the input has been read, to print out all the lines.
When this program is run with the following input:
5 I am the Five man
2 Who are you? The new number two!
4 . . . And four on the floor
1 Who is number one?
3 I three you.
its output is this:
1 Who is number one?
2 Who are you? The new number two!
3 I three you.
4 . . . And four on the floor
5 I am the Five man
If a line number is repeated, the last line with a given number overrides the others.
Gaps in the line numbers can be handled with an easy improvement to the program's END rule:
END {
for (x = 1; x <= max; x++)
if (x in arr)
print arr[x]
}
For moore information on Associate arrays, here is the link
http://www.cs.uu.nl/docs/vakken/st/nawk/nawk_80.html
Thanks
Karteek
When I was going through my projects plsql procedures, I found a block which gathers the system, user, program etc... information. SYS_CONTEXT() function was used to get this. I am putting the sample code here... DECLARE v_AUDSID NUMBER; v_DB_USER_NAME VARCHAR(20); v_EXECUTING_ENVIRONMENT VARCHAR(20); v_OSUSER VARCHAR(20); v_TERMINAL_MACHINE VARCHAR(20); BEGIN v_AUDSID := sys_context('USERENV','SESSIONID'); select USERNAME, PROGRAM, OSUSER, MACHINE into v_DB_USER_NAME, v_EXECUTING_ENVIRONMENT, v_OSUSER, v_TERMINAL_MACHINE from V$SESSION where AUDSID = v_AUDSID; DBMS_OUTPUT.PUT_LINE(v_DB_USER_NAME' ' v_EXECUTING_ENVIRONMENT' 'v_OSUSER' 'v_TERMINAL_MACHINE); END; SYS_CONTEXT(name_space, parameter_name) takes two parameters. Go to this link for more details on SYS_CONTEXT() function http://www.stanford.edu/dept/itss/docs/oracle/10g/server.101/b10759/functions150.htm Regards, Karteek
Informatica & SQL server 2000 on Windows XP - An Experience
2 comments Posted by Karteek at 5/01/2006Last week I had a good experience while I was configuring Informatica 7.1 Power Center. I created repository on MS SQL server. I did this whole setup on my Windows XP Pentium machine. It would have been easy for me if had gone for Oracle instead of SQL server as I used SQL server's windows authentication mode for creating the informatica repository. Here I am putting the details step by step.
- First I tried with My SQL database for creating repository. When I was trying to create repository I came to know that Informatica doesn't support creating repository on My SQL DB.(not sure, may be I don’t have that license).
- Then I tried with SQL server 2000. As my machine is not efficient enough to handle the load of oracle and Informatica, I opted for SQL server.
- I have two license keys for my Informatica. One is Repository key and the other is database connectivity (for Oracle, DB2, MS SQL, Teradata,…) license key.
- I installed informatica safely and the time was to configure the informatica server and repository server.
- My informatica server name is my_inf_server and repository is my_rep. While creating the repository on SQL server, I’ve chosen trusted connection i.e. using the windows authentication mode of SQL server. If we choose this option, we need not to have SQL server authentication, i.e. no username and password (which is a default setup for SQL server).
- Everything went fine until I tried to connect to the repository I created above. I was unable to connect to the repository, as it was mandatory to provide username and password for repository, which I didn’t have. Even I tried with the username that I had while configuring the repository server. Error message is could not find the username in the repository(similar to this).
- I spent lot of time in resolving this problem and started working from SQL server end. I decided to not to go for windows authentication. For that I must create a login for SQL server as we have in case of Oracle (scott, system, sys,…). I created a login from SQL server’s Enterprise Manager.
- Then I created a new repository using SQL authentication mode(Not trusted connection). Here I am putting my setup values.
Connection String : (local)@tempDB
User : sql_user
Password : *******
- With this setup I could able to successfully connect to repository by passing this username and pwd.
This was just my experience. Plz don’t take it as a standard.
I started working with informatica. I am trying to run a simple workflow (like printing Hello World in ‘C’), so that I can ensure that my setup is correct. But I am unable to make it. I am facing some errors while running the workflow. The message is similar to ‘Can’t find the dsn name xxxxx…, when the connection is ODBC and ‘Could not prepare statement’, when the connection is SQL server. I am working on this Issue. I will share the progress here…
Thanks
Karteek
Hi I am Karteek from Hyderabad, India. I am a BTech graduate. I am very fresh to the IT industry(just 4 months of work experince). I am working as a BIDW(Business Intelligence & Data Warehousing) Associate Consultant in Genpact(formerly Gecis, GE Capital Intl Services). I started my journey with SQl, PLSQL and shell scripts. Now a days I have been trying learn the DW concepts and some ETL tools like Informatica. I will share my experiences in this learing process. Your comments and suggestion are always welcome. Thank you. Karteek Hyderabad, India.
